How to run GPT prompts on many files
In this video, you’ll learn how to run GPT (Generative Pre-trained Transformer) prompts on many files simultaneously. This technique is particularly useful for automating code analysis and quality checks across large codebases.
(Also, I’ll show how we avoid paying double if we need to run something again)
This is a video for somewhat technical people. You need to be at least a junior developer. You can also copy my code from gitlab.com/tillcarlos/gpt-to-excel
I recommend you code this in your language: It took me only 4.5h of work. So you can do this, too.
If you are NOT a developer and want this tool, email me: [email protected]
Here you will learn:
- How to use it (watch the YouTube video)
- The architecture of the tool
- How to run the prompts
- How to extract a spreadsheet
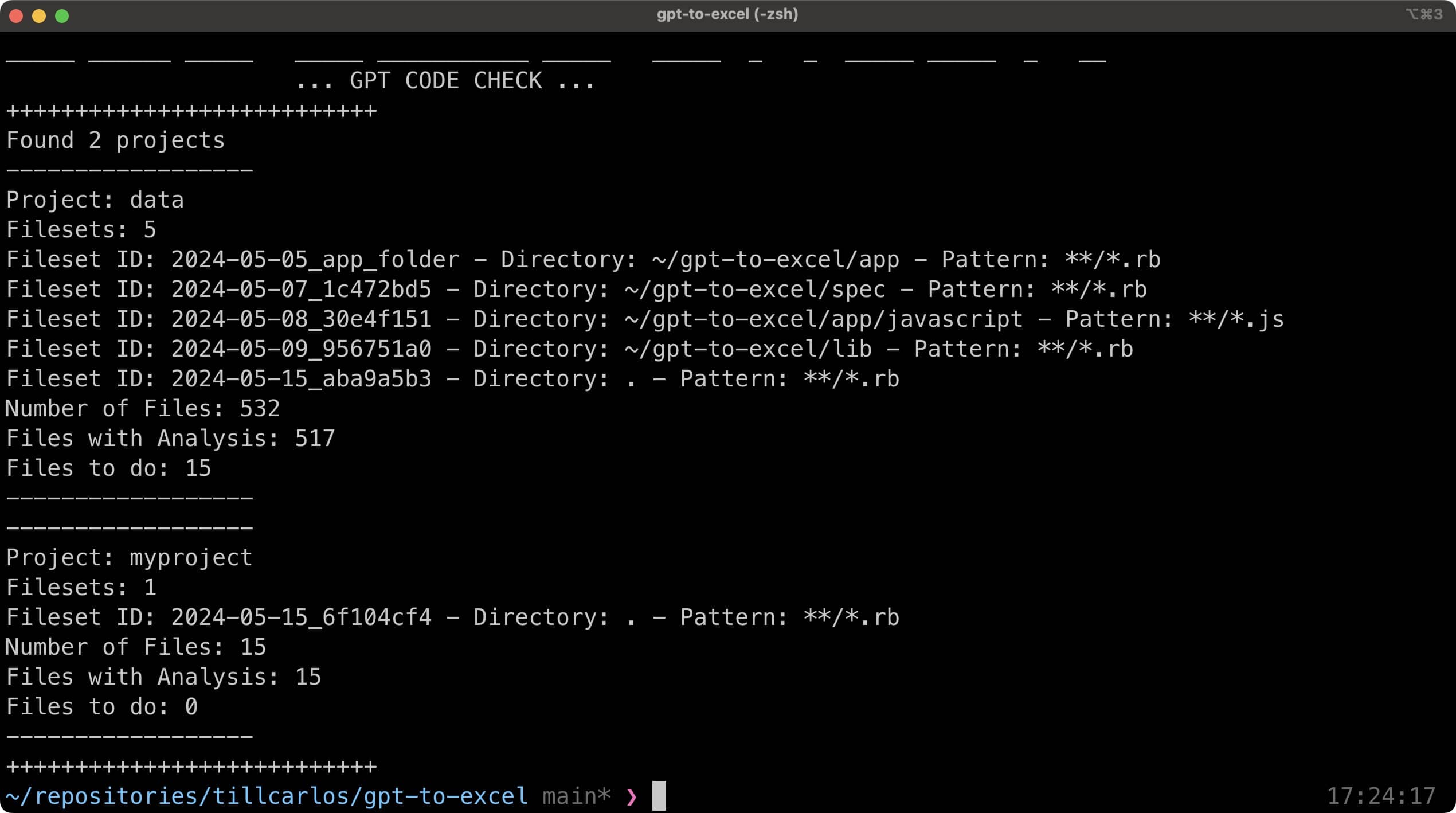
Backstory: Why did I write this?
I was taking over a project with a large codebase. I saw some flaws right away and identified areas that should be fixed. However, manually checking every file was impractical due to the sheer volume of code.
ChatGPT had helped me refactor files before, so I thought, why not run this against all files? This approach differs from simply throwing a folder into Gemini. While that might give good results too, I wanted a more granular approach and some holistic metrics about the code base.
This approach has a couple of drawbacks, but it helped me get a good overview.
Drawbacks:
- Each file is scanned separately. It gives false negatives a lot of times.
- Sometimes the severity is exaggerated.
- Works great for large files, but not great for many interconnected files - as the prompt only takes one file at a time.
Here are my design decisions and implementation details.
Write the prompt with a template
We use a specific template for our GPT prompt to ensure consistent and structured analysis:
You are an exceptionally skilled software architect with a keen eye for code quality, maintainability, and performance. You have a deep understanding of best practices and design patterns.
I’ll provide a code snippet below in ruby. Please analyze it thoroughly and provide feedback in the following JSON format. Focus on maintainability, readability, potential performance bottlenecks, and architectural flaws. ONLY respond with things I need to know.
NEUTRAL: things that are noteworthy.
MINOR: should be fixed, but won’t cause big problems.
CRITICAL: architectural problems, things that for sure need refactoring.
SEVERITY: A score from 0-1 (which we’ll use as percent). State how big of a problem that is. Over 0.5: should refactor. Over 0.8: Must fix! Over 0.9: security relevant!
CERTAINTY: State how sure you are.
Important: if a class is small it might just be a stub from a package. In that case, try not to use critical unless you are sure.
Respond in json format only. Like this:
{"neutral" : [],"minor" : [],"critical" : [],severity: 0.5,certainty: 0.5}
Here is the code: … INSERT YOUR FILE CONTENT
How we store the data
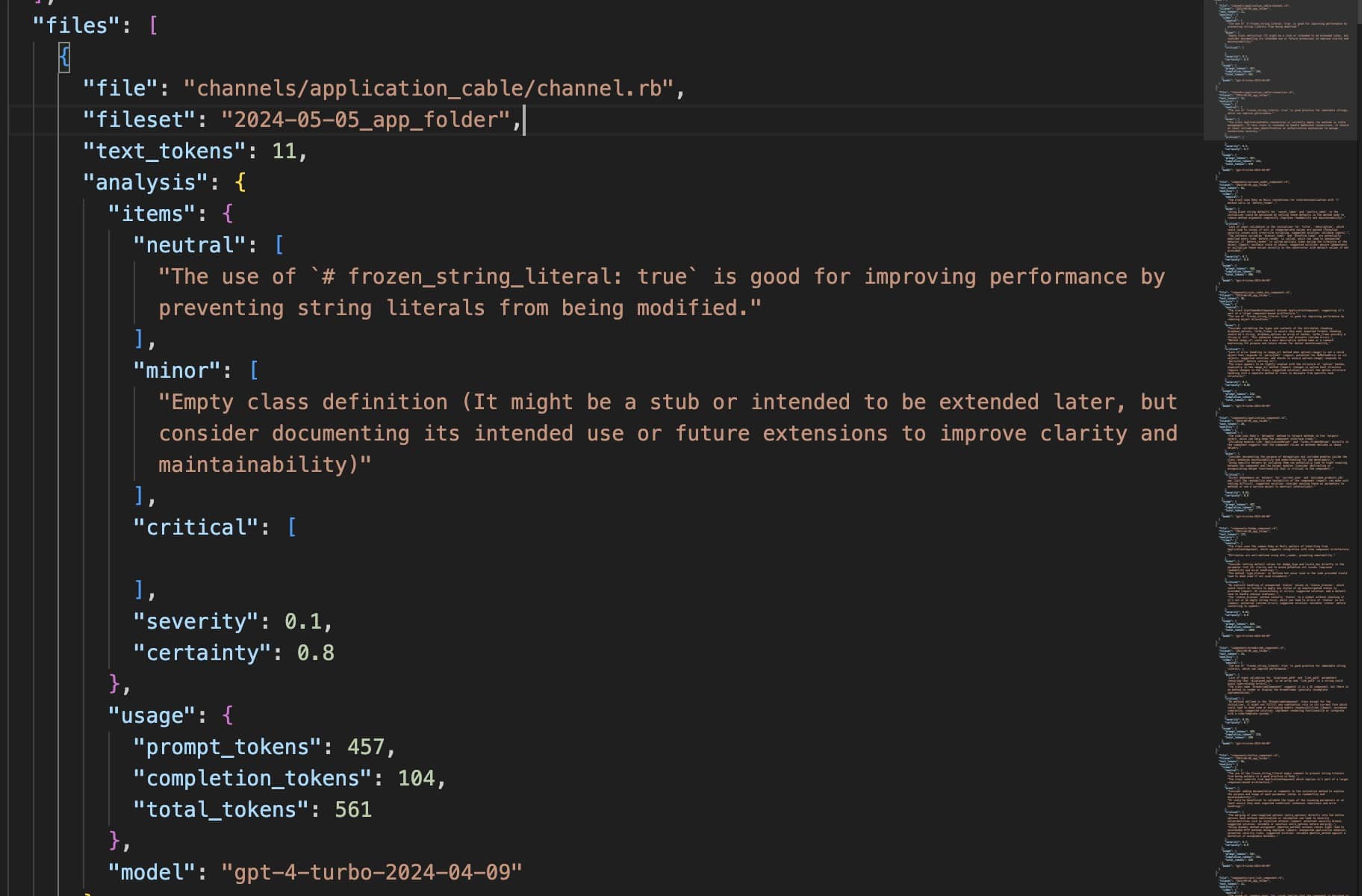
We organize our data storage to efficiently manage the GPT responses and associated metadata.
Caching the GPT Request + Results
The result then matches the md5 of the prompt, allowing us to avoid redundant API calls:

One response looks like this:
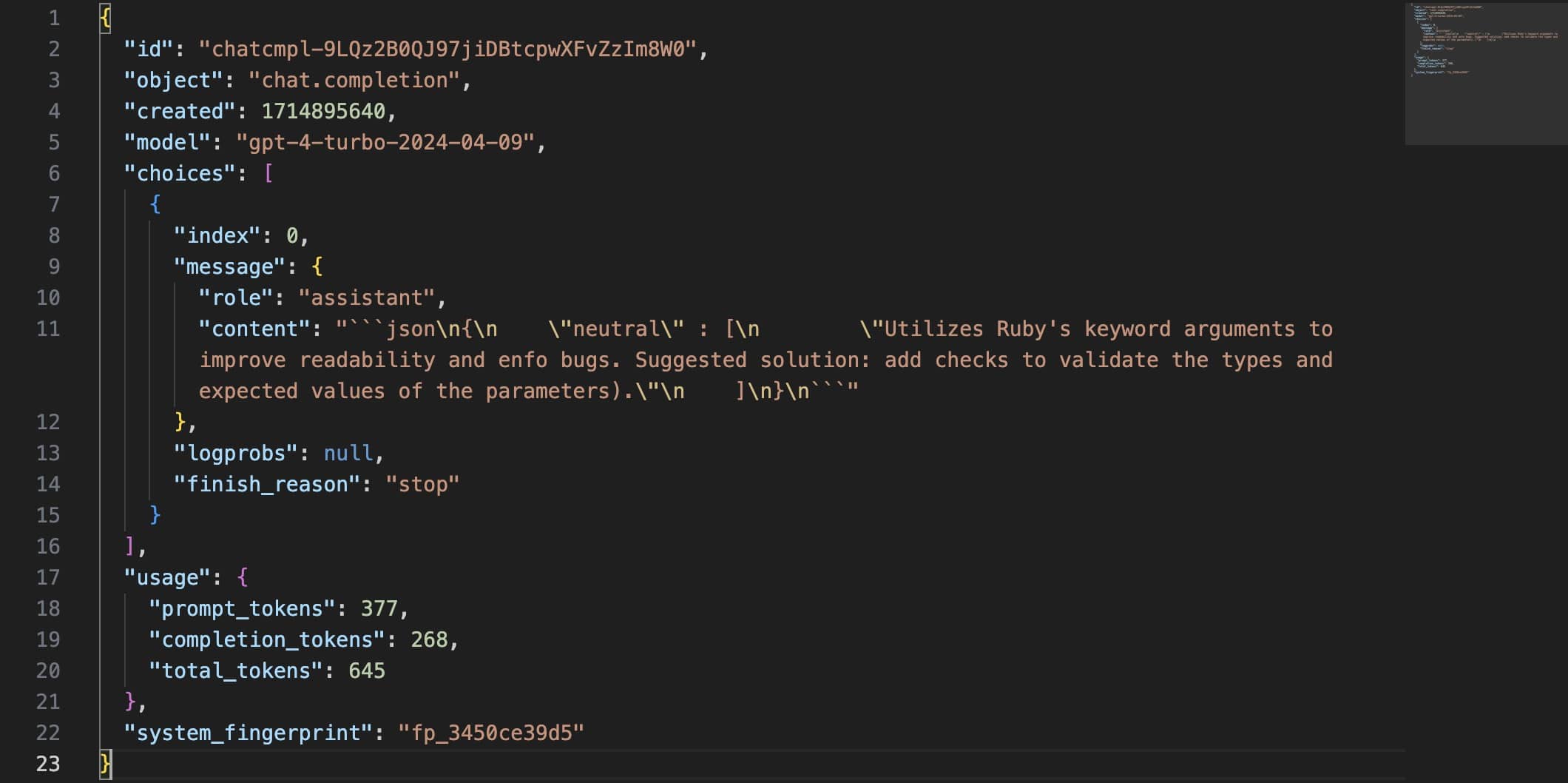
Advantages: we can re-run a file without hitting the API again, saving time and reducing costs.
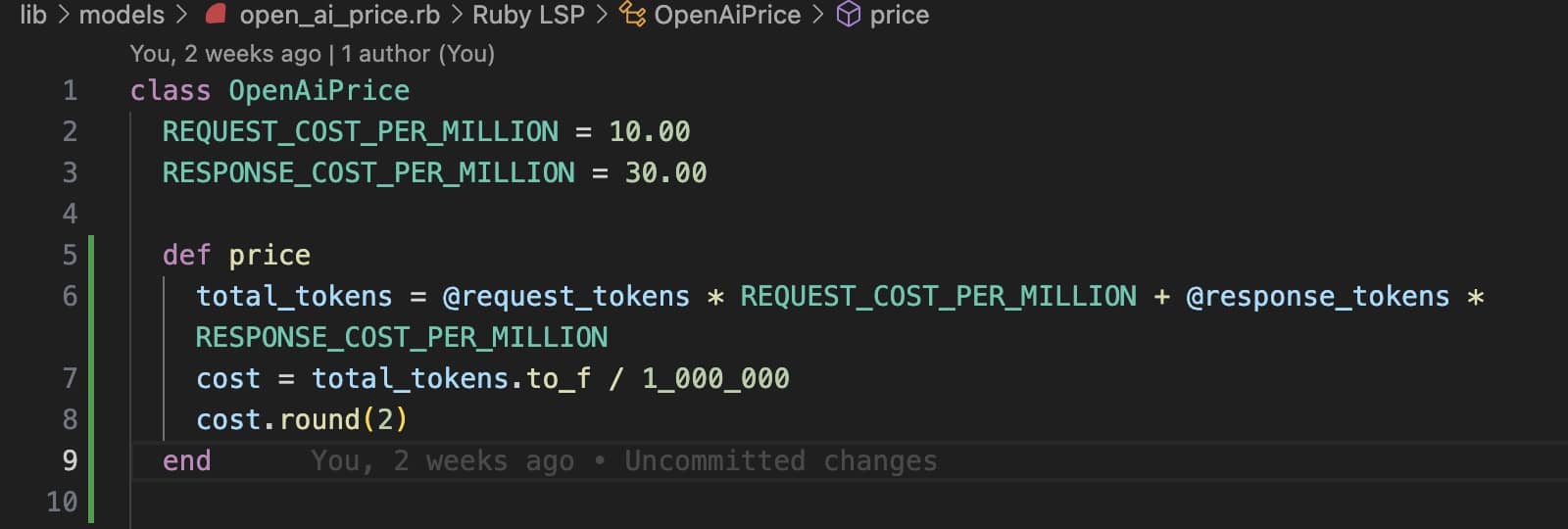
Storing the cost
We implement a cost tracking mechanism to monitor API usage:
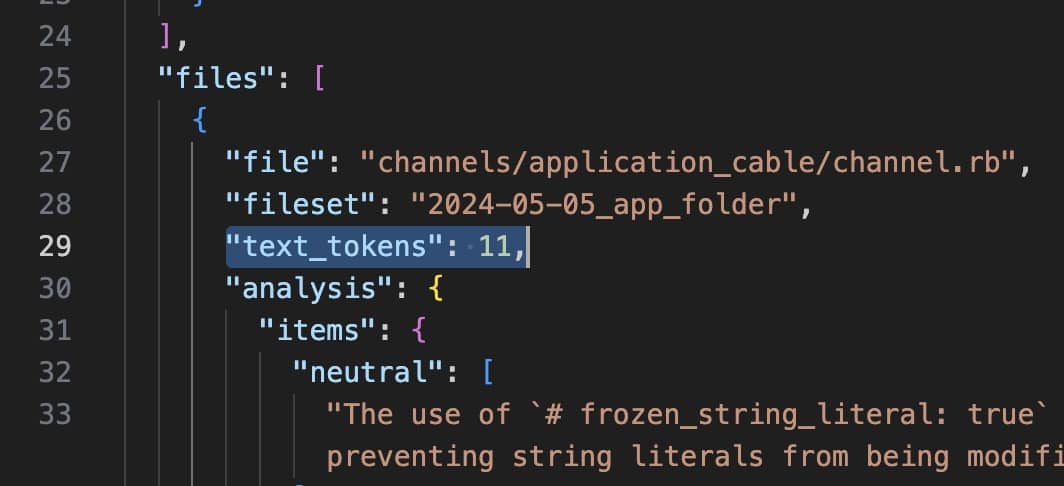
Making a cost preview
We calculate and display the expected cost based on token count:
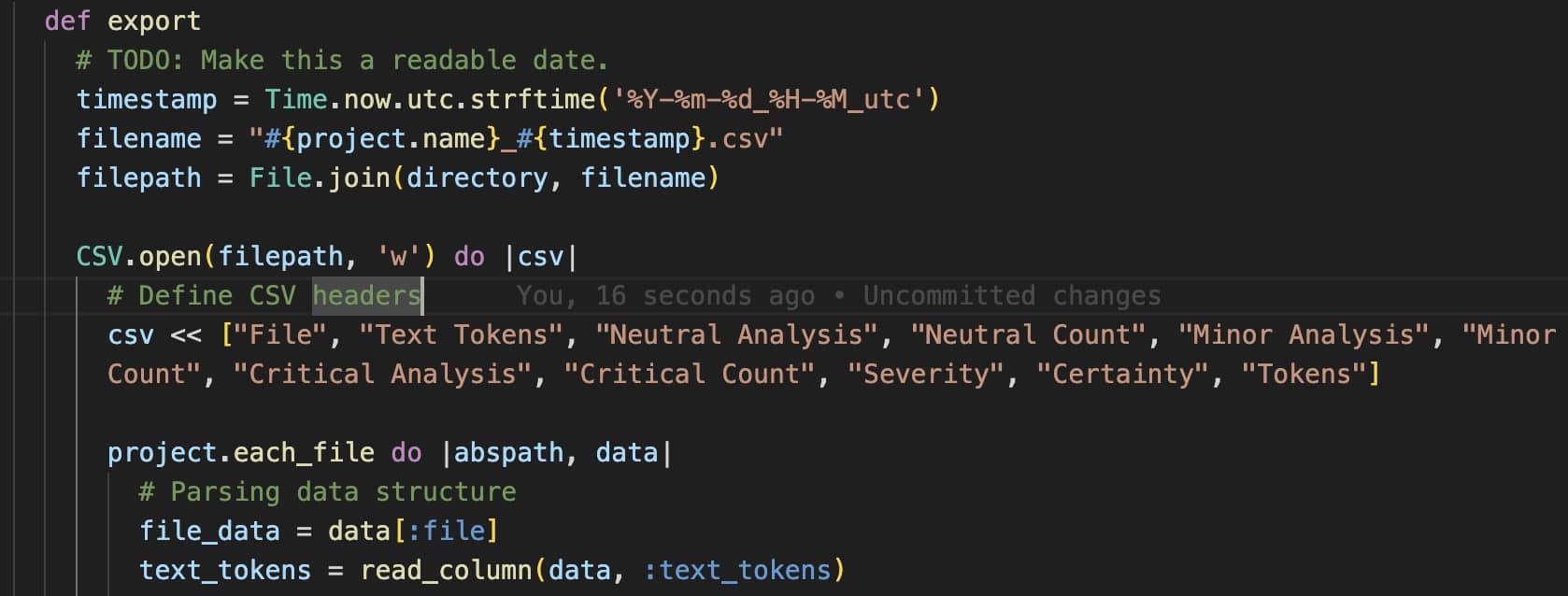
Export the data
We provide functionality to export the analysis results for further processing:
And the final result as Google Spreadsheet:
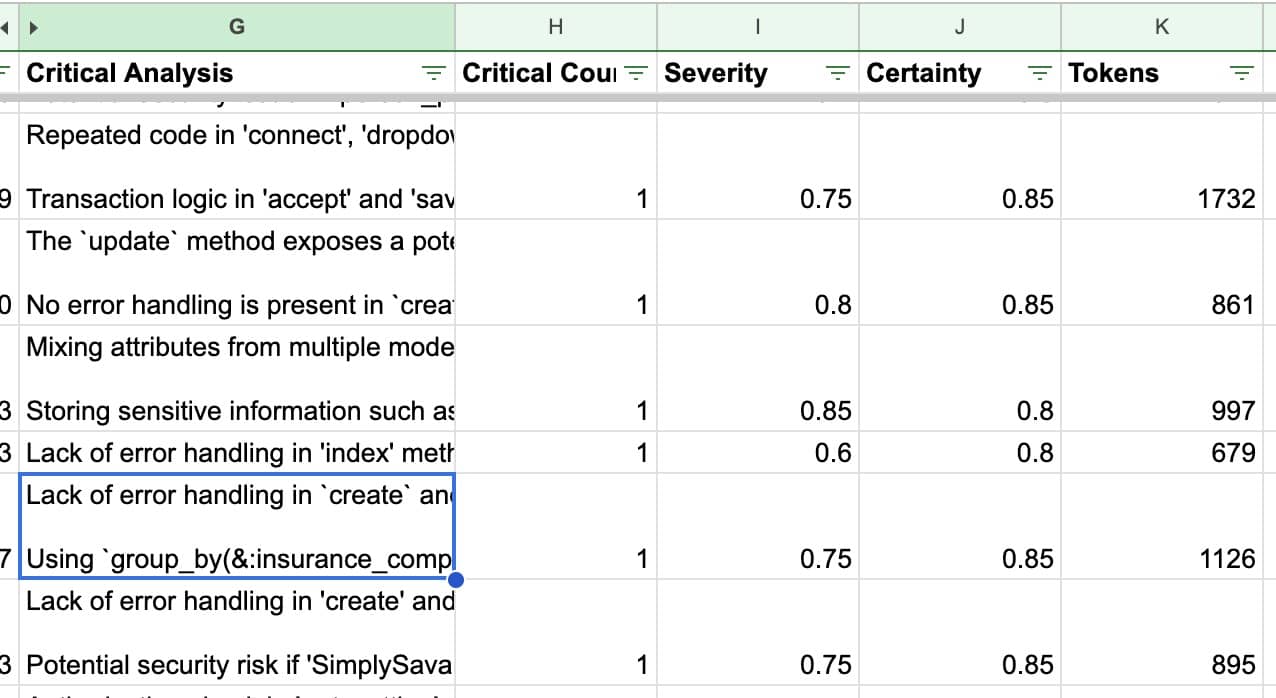
This spreadsheet allows for easy visualization and analysis of the code quality metrics across the entire project. If you want more in-dept insight check out my full video on here
